SQLiteSpy官方版是一款快速紧凑的拥有图形界面的SQLite数据库管理工具,帮助用户读取sqlite3的文件和对他们的SQL语句进行执行,因为采用了图形界面所以对于许多用户来说使用起来更加简单,而且软件完全免费,更是许多个人用户和学习数据库的用户比较喜欢的一款教育软件。
该软件具有数据库一览的功能梳妆显示所有的架构,包括表、列、索引等在数据库中保含的项目,还可以通过按F5更新架构树,双击一个表或视图来显示他的数据,使用常用的命令轻松完成各种数据库操作,非常方便且实用。

主要特点
1、数据库一览
树状显示所有的架构,包括表,列,索引和触发器在数据库中包含的项目。按F5更新架构树,双击一个表或视图来显示它的数据,使用常用的命令的上下文菜单。
2、网格单元格编辑
表格单元格中编辑:显示一个表通过树状架构,选择一个单元格,然后按F2键调用编辑器。然后修改并确认您的更改写回到谈判桌上。
3、数据类型显示
本机的SQL数据类型显示不同的背景颜色来帮助检测类型错误。类型错误可能会导致性能下降或错误的SELECT结果集,如果NULL值与空字符串混淆。
4、完全的Unicode? SQLiteSpy完全支持SQLite的Unicode的能力。数据显示和输入是完全实现为Unicode,包括SQL命令。
5、多个SQL编辑
现代标签是用来编辑和显示的查询语句和结果比较容易多个SQL查询。 SQL查询执行输入或加载到SQL他们编辑。然后按F9键运行该查询,或Ctrl + F9来运行当前行或选择只。
6、时间测量
SQL执行的时间会自动测量和显示,以帮助优化查询。
7、正则表达式
在SQL关键字regexp是支持,并增加了完整的Perl的正则表达式语法5.10 SQLiteSpy。的实施,实现了利用DIRegEx库。
8、数学SQL函数
下面的SQL函数可用数学除了SQLite的默认:ACOS(), ASIN(), ATAN(), ATAN(), ATAN2(), CEIL(), CEILING(), COS(), COT(), DEGREES(), EXP(), FLOOR(), LN(), LOG(), LOG(), LOG2(), LOG10(), MOD(), PI(), POW(), RADIANS(), SIGN(), SIN(), SQRT(), TAN(), TRUNCATE().
9、数据压缩
压缩的SQL函数()适用的zlib的紧缩到任何文本或BLOB值。原始紧缩数据流返回。解压缩()膨胀此流回到原来的。整数,双打,并返回空值不变。
10、紧凑型结果储存
内部数据存储机制使用,以达到最佳的兼容性SQLite的原生数据类型。因此,SQLiteSpy使用远低于其它的SQLite管理内存和更有效地处理大量的表。
11、内建的SQLite引擎
SQLiteSpy来已建成为一个单一的应用程序文件与SQLite数据库引擎可执行文件。有没有需要分发任何DLL,这使得SQLiteSpy易于部署的客户。
12、加密支持
SQLiteSpy可以阅读和修改加密的数据库文件由DISQLite3产生。 DISQLite3实现了自己的母语AES加密这是不符合商业SQLite的加密扩展(SSE)的或任何其他第三方的实施提供兼容。
13、易安装和卸载
要运行SQLiteSpy,只需提取SQLiteSpy.exe文件到任何目录和执行文件。不需要安装?刚开始时,该程序创建一个文件SQLiteSpy.db3(1 sqlite3的数据库)来存储的和设置。它不写任何其他文件或注册表。卸载一样只是简单的删除两个文件:应用程序的可执行文件和数据库文件的选项。
使用教程
1、新建一个数据库:
File->New Database,起名为SqlLearning。如下图:

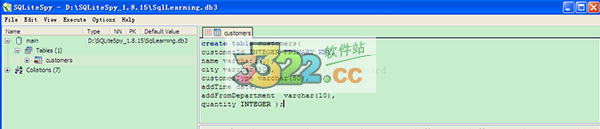
2、sql语句输入区输入如下语句,按快捷键F9,创建数据库表customers。执行后效果如下图。
[sql] view plaincopy
create table customers(
customerId INTEGER PRIMARY KEY,
name varchar(50),
city varchar(50),
customerType varchar(50),
addTime date,
addFromDepartment varchar(10),
quantity INTEGER );
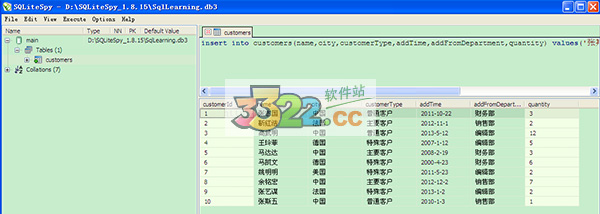
3、sql语句输入区域分别输入如下的10个sql语句,插入10条记录。执行后的效果如下图。
[sql] view plaincopy
insert into customers(name,city,customerType,addTime,addFromDepartment,quantity) values('张志国','中国','普通客户','2011-10-22','财务部',3) ;
insert into customers(name,city,customerType,addTime,addFromDepartment,quantity) values('靳红浩','法国','主要客户','2012-11-1','销售部',2) ;
insert into customers(name,city,customerType,addTime,addFromDepartment,quantity) values('高武明','中国','普通客户','2013-5-12','编辑部',12) ;
insert into customers(name,city,customerType,addTime,addFromDepartment,quantity) values('王玲菲','德国','特殊客户','2007-1-12','编辑部',5) ;
insert into customers(name,city,customerType,addTime,addFromDepartment,quantity) values('马达达','中国','主要客户','2008-2-19','财务部',3) ;
insert into customers(name,city,customerType,addTime,addFromDepartment,quantity) values('马凯文','德国','特殊客户','2000-4-23','财务部',6) ;
insert into customers(name,city,customerType,addTime,addFromDepartment,quantity) values('姚明明','美国','特殊客户','2011-5-23','编辑部',2) ;
insert into customers(name,city,customerType,addTime,addFromDepartment,quantity) values('余铭宏','中国','主要客户','2012-12-2','销售部',7) ;
insert into customers(name,city,customerType,addTime,addFromDepartment,quantity) values('张艺谋','法国','特殊客户','2013-1-2','编辑部',2) ;
insert into customers(name,city,customerType,addTime,addFromDepartment,quantity) values('张斯五','中国','普通客户','2010-1-3','销售部',1);
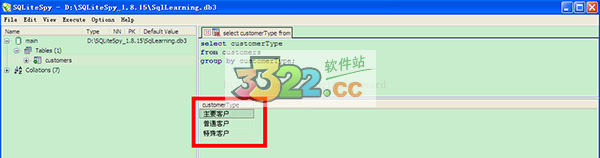
4、对customers根据customersType进行分组。
[sql] view plaincopy
select customerType from customers group by customerType;
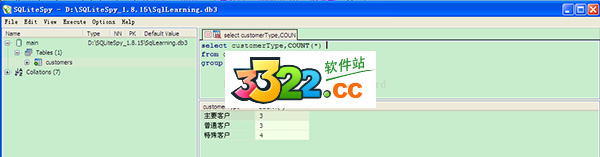
5、group by 常和 sum,max,min,count等聚合函数一起使用,例如:对 customers根据 customersType进行分组统计每个类别中的客户个数。
[sql] view plaincopy
select customerType,COUNT(*) from customers group by customerType ;
6、 例如:对 customers根据 customersType进行分组获取每组的最大customersId
[sql] view plaincopy
select customerType,MAX(customerId) as number from customers group by customerType ;
注:as number相当于起了个别名,如果不起别名的话将会显示为”MAX(customerId)“
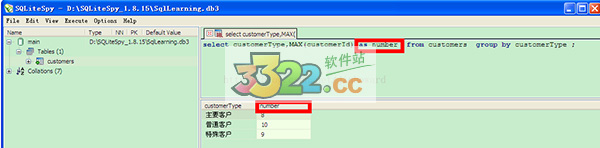
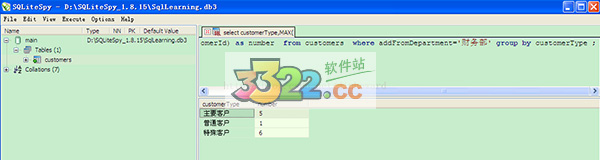
7、group by 字句和where字句一起使用,在SQL中where字句的运行顺序是先于 group by 字句的,where字句会会在形成组和计算列函数之前消除不符合条件的行
例如:查询由财务部门添加的用户中各个类型的最大customersId
[sql] view plaincopy
select customerType,MAX(customerId) as number from customers where addFromDepartment='财务部' group by customerType ;
where字句过滤掉了不是财务部添加的用户信息,group by对where字句的结果又进行了分组操作,没有groupby的话得到的记录将是财务部添加的用户中customerId最大的一条记录。
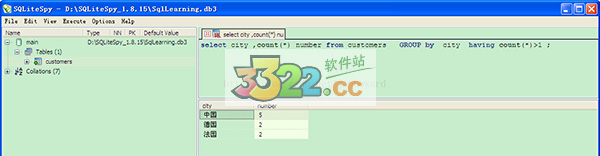
8、group by字句和having()字句一起使用,在SQL中 having()字句的运行顺序是后于group by字句的, having()字句的的作用是筛选满足条件的组,例如:查询客户数超过1个的国家和客户数量。
[sql] view plaincopy
select city ,count(*) number from customers GROUP by city having count(*)>1 ;
分析:系统会先对customers根据 city 分组,生产虚拟表,之后having字句对生成的虚拟表进行筛选,将数量不大于1的剔除
更新日志
v1.9.11版本
1、升级内置DISQLite3引擎到SQLite 3.13.0
2、新增JSON(基于JavaScript语言的轻量级数据交换格式)扩展选项
例如:SELECT json_extract('{“a”:2,“c”:[4,5,{“f”:7}]}', '$.c[2].f');
3、新增Session扩展
例如:SELECT * FROM generate_series(0,100,5)。









